

Day 1 - A beginners guide to LLMs ( and transformer architecture )
Attention is all you need!

This is the first article of my 75 Days Of Generative AI series where I try to build and learn to unravel mysteries of Generative AI and LLMs for myself and the world!
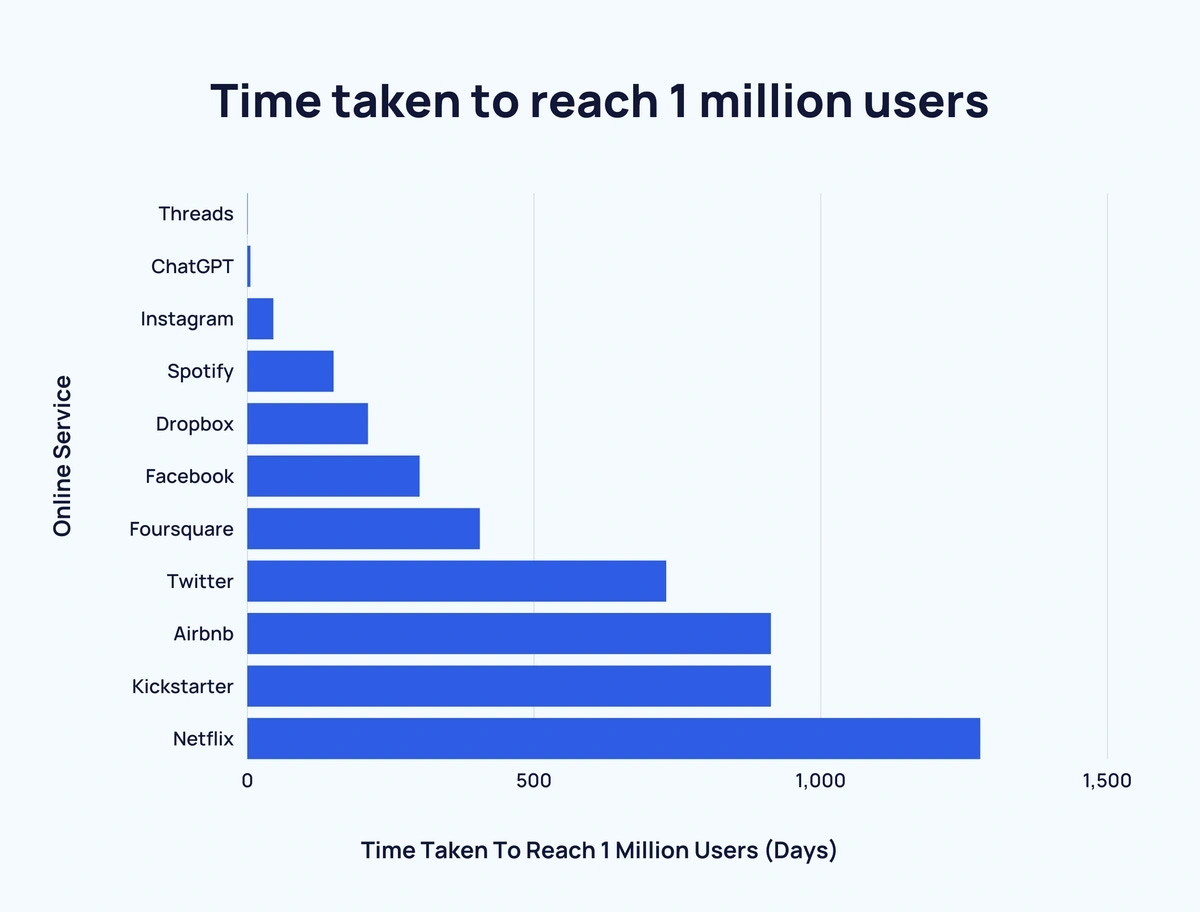
Even though language models have been around forever, LLMs took center stage when GPT3 in November 2022. According to OpenAI, ChatGPT acquired 1 million users just 5 days after launching
But what are LLMs and how do they feel so magical in generating information on providing such a simple instruction? Lets dive in!
TLDR; If you want to visualize how an LLM works, here is an awesome step-by-step 3D visualization.
The Transformer Architecture: A Game-Changer
Language models have been around for a while. A language model is a machine learning model designed to predict the next word in a sentence based on the previously provided words. A common example of language models in everyday use is the predictive text feature on smartphone keyboards, which suggests the next word based on your current input.
Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks were the state-of-the-art models till 2017 but everything changed post-release of the paper Attention Is All You Need.
Transformers worked better than earlier models mainly on 3 aspects
Process entire sequences in parallel, improving efficiency
Handle long-range dependencies more effectively
Scale better with increased data and computational resources
Transformer Architecture
The transformer model comprises 2 components, an encoder, and a decoder stacked over each other to form what we call a transformer model.

Understanding Attention Mechanism
The self-attention mechanism is the heart of the Transformer. It allows the model to weigh the importance of different words in a sentence when processing each word. Imagine reading a sentence and, for each word, deciding how much to focus on every other word to understand its meaning and context.

Self-attention excels in language tasks because:
It captures relationships between words regardless of their position in the sentence
It can handle ambiguity by considering multiple interpretations
It allows the model to focus on relevant parts of the input for different tasks
From Transformers to Modern LLMs
The evolution of Transformer-based models has been rapid:
BERT (2018): Introduced bidirectional training, improving understanding of context
GPT (2018) and GPT-2 (2019): Focused on generative tasks with increasing model sizes
GPT-3 (2020): Demonstrated impressive few-shot learning capabilities
Challenges and Limitations
Bias and ethical concerns
Reflecting biases present in training data
Potential for generating misleading or false information
Privacy concerns regarding the use of personal data in training
Computational requirements
High energy consumption for training
Expensive hardware requirements
Challenges in deployment on resource-constrained devices
As we continue to push the boundaries of what's possible with Large Language Models, we're only beginning to scratch the surface of their potential impact on society and technology. While challenges remain, the future of AI-powered language understanding and generation looks incredibly promising.
In the coming days, I will delve deeper into core concepts of development with LLM like Instruction dataset, Pretraining, Supervised Fine Tuning, and Preference alignment.
References
https://jalammar.github.io/illustrated-gpt2/