

Day 27-30: From Lab to Production - Observability for Multi-Agent Systems with Opik


Welcome back to my #75DaysofGenerativeAI series! After building our personal finance multi-agent application using LangGraph over the past few weeks, it's time to take the crucial step from development to production. Today, we're diving deep into observability - the critical bridge between "it works on my machine" and "it works reliably in production."
In this comprehensive guide, we'll implement production-grade observability for our personal finance app using Opik, an open-source LLM evaluation and monitoring platform. This isn't just theory - we're building a complete monitoring stack that you can deploy today.
Why Observability Matters for Multi-Agent Systems
Before we dive into implementation, let's understand why observability is critical for multi-agent LLM applications
. Unlike traditional applications, multi-agent systems present unique challenges:
Complex Interaction Patterns: When multiple agents collaborate, understanding the flow of data and decisions becomes exponentially more complex. A single user request might trigger a cascade of agent interactions, each with its own success criteria and failure modes.
Non-Deterministic Behavior: LLMs introduce stochastic elements that make debugging traditional approaches inadequate. The same input can produce different outputs, making it essential to track not just what happened, but the confidence and reasoning behind each decision.
Cost and Performance Implications: Multi-agent systems can quickly consume significant LLM API credits. Without proper monitoring, a seemingly minor inefficiency can result in exponential cost increases.
Production Reliability: In financial applications, reliability isn't optional. Every transaction processing failure or categorization error directly impacts user trust and regulatory compliance.
Introducing Opik: Open-Source LLM Observability
Opik is a powerful open-source platform created by Comet specifically for LLM applications. Unlike generic monitoring tools, Opik understands the unique challenges of LLM applications:
Native LLM Support: Built-in integrations for tracking prompts, completions, and costs
Multi-Agent Awareness: Designed to handle complex agent workflows and interactions
Production Ready: Scales to millions of traces with enterprise-grade performance
Evaluation Framework: Includes LLM-as-a-judge metrics for automated quality assessment
Open Source: Full transparency and customizability for your specific needs
Understanding Opik Integration
Opik is used heavily within the application for tracking operations and data processing, particularly with external services, ensuring tractability and debuggability.
Usage in Statement Processing Workflow
In the statements.py file ( fastAPI ), opik is initially imported and then used to decorate asynchronous functions, enhancing the ability to track workflow processes.
To ensure all the calls are under one trace, we manually setup tracing supported by opik
trace = opik_client.trace(name="process_statement_manual_trace")
trace.update(output={"status": "success", "transaction_count": len(results)})
# ensure the trace is closed always
finally:
trace.end()
Tracking the calls
Firstly, in application/workflows/statement_processing.py, opik is utilized for tracking the flow of data through the system, beginning from document parsing to the final storage in a vector database.
from opik import track
@track()
async def process_statement_workflow(file_path: str, user_id: str) -> OutputState:
...
Workflow Decorator:
To start, the transaction processing workflow is tracked with opik's @track() decorator:
from opik import track
@track()
async def process_statement_workflow(file_path: str, user_id: str) -> OutputState:
...
opik Tracing in Vector Database Agent
In application/agents/vector_db_agent.py, opik facilitates tracking complex data processing operations, particularly while interfacing with external vector database solutions like Weaviate.
class GenericVectorDBIngestor:
@track()
def normalize_transaction_with_perplexity(self, item: Dict[str, Any]) -> Dict[str, Any]:
...
@track()
def ingest_data(self, data: List[Dict[str, Any]], batch_size: int = 100):
...
open_ai trace for LLM Tracking
For LLM Tracking I had to make a change from my previous implementation. Previously, we we doing a direct call to perplexity api for normalization of data. But opik doesn’t capture this as an LLM Call. Hence the approach to do so is to wrap perplexity call around open_ai chat since perplexity is open ai compatible
from opik.integrations.openai import track_openai
from openai import OpenAI
class GenericVectorDBIngestor:
def __init__(self, collection_name: str):
...
api_key = os.getenv("PERPLEXITY_API_KEY", "your_api_key_here")
openai_client = OpenAI(
api_key=api_key,
base_url="https://api.perplexity.ai"
)
self.perplexity_client = track_openai(openai_client)
followed by
@track()
def normalize_transaction_with_perplexity(self, item: Dict[str, Any]) -> Dict[str, Any]):
prompt = f"..."
try:
response = self.perplexity_client.chat.completions.create(
model="sonar",
messages=[{"role": "user", "content": prompt}],
temperature=0.1,
max_tokens=4000
)
...
The result is a clear scan to understand whats happening
Here is the output
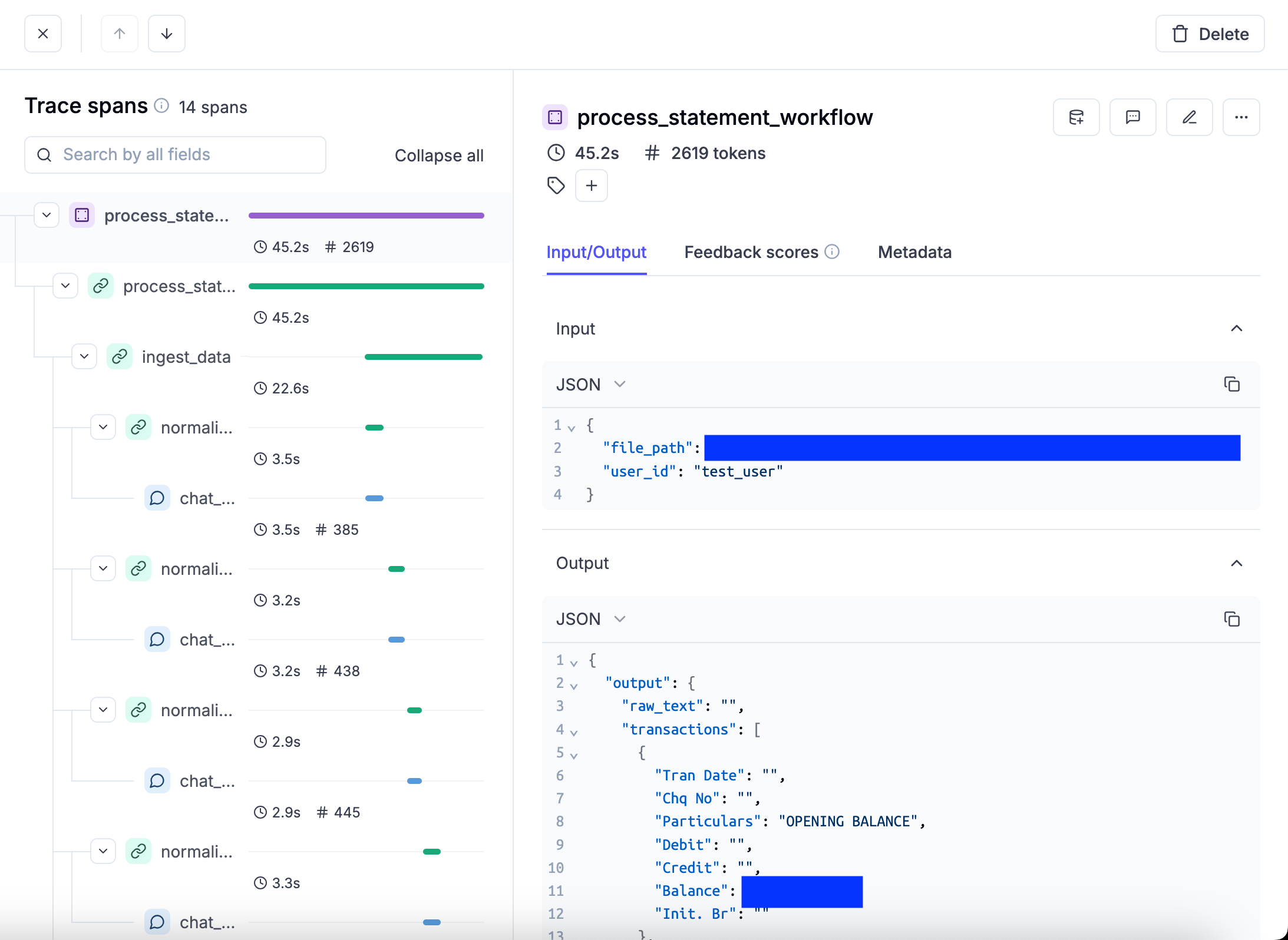
And for a specific LLM call for normalisation
Input

Output

Conclusion
Building observable multi-agent systems is not optional for production applications - it's essential for reliability, cost control, and continuous improvement
Through this implementation, we've created a comprehensive observability stack that provides:
Real-time visibility into agent performance and system health
Proactive alerting to prevent issues before they impact users
Cost optimization insights to manage LLM expenses effectively
Compliance support for financial regulatory requirements
Performance optimization data to continuously improve the system
The journey from lab to production is complex, but with proper observability, it becomes manageable and even enjoyable. You gain confidence in your system's behavior and the insights needed to make it better every day.
This article is part of my #75DaysofGenerativeAI series. Follow along for more practical implementations and real-world insights into building production-grade AI systems.