

Day 3 - Making of a Personal Assistant ( Part 2 )
When a measure becomes a target, it ceases to be a good measure


This is the third installment of my 75 Days Of Generative AI series. In my previous article, I explained how LLMs are fine-tuned to become personal assistants. Today I’ll cover one more critical topic - evaluation. For a refresher here are the important steps of the journey
These steps include
Pre-training models - previous article
Supervised Fine-Tuning - previous article
Preference Alignment - previous article
Evaluation of model
Evaluation of model
Evaluating Large Language Models (LLMs) is a crucial yet often underappreciated component of the AI development pipeline. This process can be time-consuming and presents challenges in terms of reliability and consistency. When designing your evaluation strategy, it's essential to align your metrics with the specific requirements of your downstream task.
Traditional metrics
These metrics operate on the character/word/phrase level.
Word Error Rate (WER):
Used primarily in speech recognition and machine translation
Measures the edit distance between a reference text and the system output
Calculated as: (Substitutions + Insertions + Deletions) / Number of Words in Reference
Lower WER indicates better performance
Exact Match (EM):
Used in question answering and other tasks requiring precise answers
Binary metric: 1 if the predicted answer exactly matches the reference, 0 otherwise
Simple but strict; doesn't account for partial correctness
BLEU (Bilingual Evaluation Understudy):
Primarily used in machine translation
Measures the overlap of n-grams between the reference and candidate translations
Scores range from 0 to 1, with 1 being a perfect match
Criticized for not always correlating well with human judgments
ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
Used mainly in text summarization
Measures the overlap between generated summaries and reference summaries
Various versions: ROUGE-N (n-gram overlap), ROUGE-L (longest common subsequence), etc.
Higher ROUGE scores indicate better performance
Embedding Based Methods
These methods leverage the power of dense vector representations of words, sentences, or documents to assess similarity and quality in a more nuanced way than traditional lexical-matching metrics.
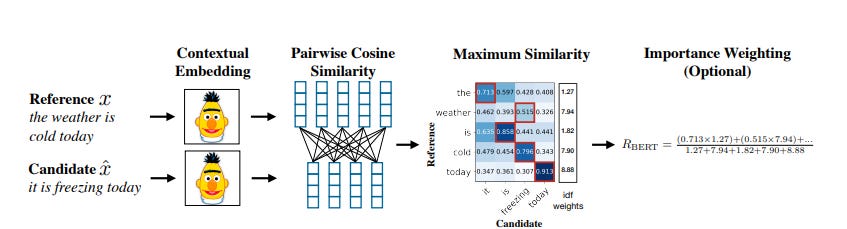
BERTScore (https://arxiv.org/pdf/1904.09675):
Uses contextual embeddings from models like BERT
Computes pairwise cosine similarities between tokens in candidate and reference texts
Claims to correlate better with human judgments than traditional metrics
MoverScore (https://arxiv.org/pdf/1909.02622):
Combines Word Mover's Distance with contextual embeddings
Balances semantic similarity with token importance


BLEURT (Bilingual Evaluation Understudy with Representations from Transformers https://arxiv.org/pdf/2004.04696):
Fine-tunes a pre-trained language model on human ratings
Produces a learned metric that correlates well with human judgments
Human evaluation
While quantitative metrics provide valuable insights, the ultimate measure of a language model's effectiveness often lies in its real-world performance and user satisfaction. Human evaluation and user feedback remain the gold standard for assessing the quality and utility of AI-generated content. Here's an improved version of the text:
The most reliable evaluation of language models often comes from two key sources: user acceptance rates and human comparisons. These qualitative assessments provide crucial insights that automated metrics may miss:
User Acceptance Rate: This measures how often users find the model's outputs satisfactory or useful in real-world scenarios. It directly reflects the model's practical value and alignment with user needs.
Human Comparisons: Controlled studies where human evaluators compare outputs from different models or against human-generated content can reveal nuanced differences in quality, coherence, and appropriateness.
To maximize the value of these evaluations, it's essential to implement robust feedback mechanisms. Systematically logging user feedback alongside complete interaction logs (for example, using tools like LangSmith) creates a rich dataset for analysis.
Tools
OpenAI Evals:
Developed by OpenAI
Provides a framework for evaluating language models on various tasks
Allows custom evaluation creation and sharing
GitHub: https://github.com/openai/evals
Ragas:
An open-source framework for evaluating Retrieval Augmented Generation (RAG) systems
Offers metrics for context relevance, faithfulness, and answer relevance
LangSmith:
Developed by LangChain
Provides tools for debugging, testing, and monitoring LLM applications
Offers features for logging, tracing, and analyzing model outputs
Website: https://www.langchain.com/langsmith
EleutherAI LM Evaluation Harness:
A comprehensive tool for evaluating language models on a wide range of tasks
Supports various model architectures and provides standardized benchmarks
Hugging Face Evaluate:
Part of the Hugging Face ecosystem
Provides a wide range of evaluation metrics and datasets
Easily integrates with Hugging Face models and datasets
Key features of these tools:
Metrics: Most tools offer a range of metrics, from traditional ones like BLEU to more advanced embedding-based metrics.
Customization: Many allow users to define custom evaluation tasks and metrics.
Benchmarks: Several tools provide standardized benchmarks for comparing different models.
Integration: Tools like LangSmith offer integration with development workflows for continuous evaluation.
Visualization: Many tools provide dashboards or visualization capabilities for easier interpretation of results.
Multi-task Evaluation: Tools like HELM and EleutherAI's harness evaluate models across a wide range of tasks.
When choosing an evaluation tool, consider:
The specific tasks and metrics relevant to your use case
Integration with your existing workflow and model architecture
The level of customization and flexibility you need
The tool's active development and community support
Conclusion
Comprehensive evaluation of Large Language Model (LLM) based applications is a critical step in the development pipeline, particularly before moving to production. This process serves multiple essential functions:
Quality Assurance: Rigorous evaluation acts as a crucial quality check, ensuring that the application meets predetermined performance standards and user expectations.
Performance Optimization: By identifying strengths and weaknesses, evaluation guides targeted improvements to enhance the overall performance of the LLM pipeline.
Risk Mitigation: Thorough testing helps uncover potential issues such as biases, inconsistencies, or failure modes, allowing for preemptive solutions.
Benchmarking: Evaluation provides a baseline for comparing different models, architectures, or versions of your application.
Remember, evaluation should not be viewed as a one-time checkpoint, but rather as an integral, ongoing part of the LLM application development and maintenance process. As the field of AI rapidly evolves, staying current with the latest evaluation techniques and regularly reassessing your metrics will be key to maintaining competitive, high-quality LLM-based applications.
If you like this series, subscribe to my newsletter or connect with me on LinkedIn.
References
All about evaluating Large language models
Evaluating Large Language Model (LLM) systems: Metrics, challenges, and best practices