

Day 33 : Why your AI product is just a prototype without proper evaluation

Welcome back to my #75DaysofGenerativeAI series! Today we are going to go through an overview of evals for LLMs.
Building with LLMs feels like magic until reality hits. Your chatbot works perfectly in demos but falls apart with real users. Your content generator produces gold one day and garbage the next. Sound familiar?
The problem isn't your prompts or your model choice.
You're flying blind without proper evaluation.
Here are ideas that will transform how you think about AI quality
Stop Chasing Benchmarks, Start Testing Your Product
Here's the hard truth: LLM evaluation ≠ benchmarking. Those shiny MMLU scores and coding benchmarks? They're like school exams testing general skills. But you're not building a general-purpose AI - you're solving specific problems.
If you're building a customer support bot, don't care about its math skills. Test whether it can ground answers in your company policies without hallucinating competitor information. Different use cases demand completely different evaluation priorities.
LLM evaluation ≠ benchmarking
Evaluation is not a one time task
Think of evaluation as a tool that evolves with your product lifecycle. Each stage demands different approaches and effort allocation.
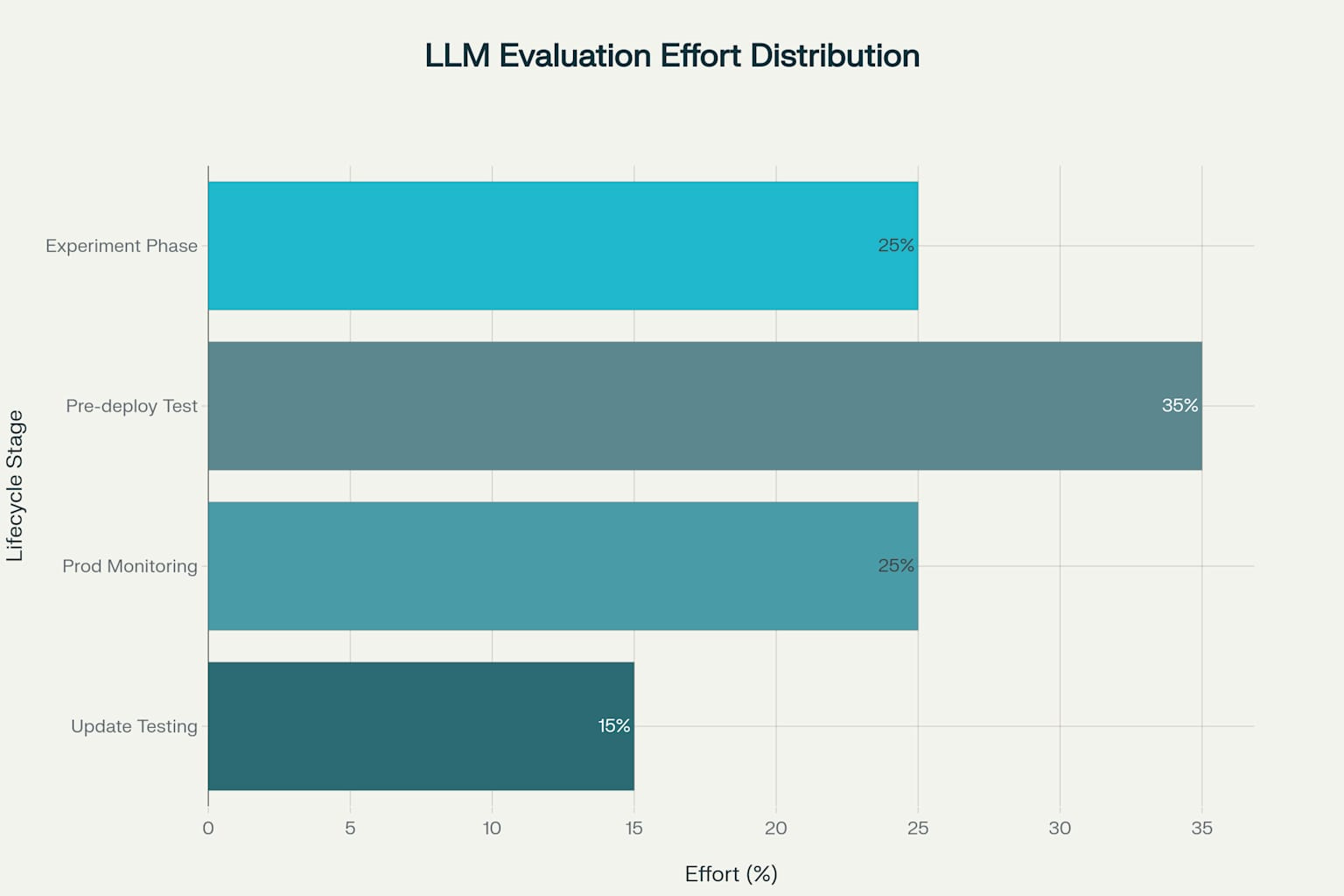
The data shows that pre-deployment testing should consume 35% of your evaluation effort - more than any other single stage. This isn't accidental. It's your last chance to catch catastrophic failures before users do.
During experiments: Which prompt performs better - A or B?
Before deployment: Can adversarial inputs break your system?
In production: Are users getting stuck or seeing hallucinations?
During updates: Will this bug fix break something else?
LLMs Broke Traditional Software Testing
Traditional software testing assumes deterministic behavior. Input X always produces Output Y. LLMs shattered this assumption.
Now you're dealing with:
Non-deterministic outputs (same input, different responses)
Brittle prompts (punctuation changes can alter behavior)
Open-ended tasks (what makes a "good" email?)
New failure modes (hallucinations, jailbreaks, data leaks)
You can't just test functionality anymore - you need to evaluate content quality and safety.
Master Both Reference-Based and Reference-Free Evaluation
Understanding when to use each evaluation approach is critical for building robust LLM systems
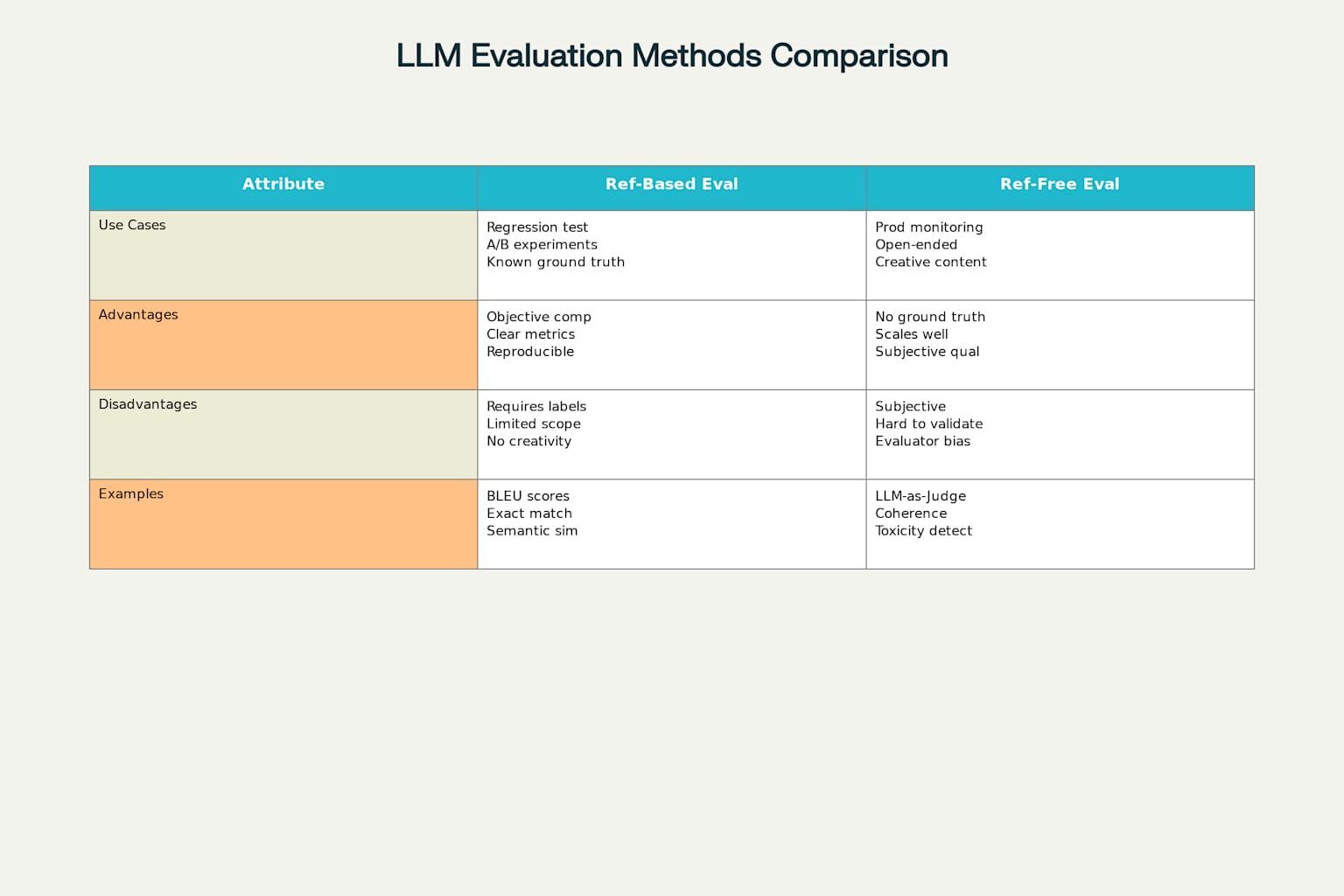
Reference-based evaluation compares outputs against expected answers - perfect for regression testing and experiments where you have ground truth. Reference-free evaluation judges responses independently, essential for production monitoring and open-ended scenarios where there's no single "correct" answer.
You need both in your toolkit. The matrix above shows exactly when each approach excels and where they struggle.
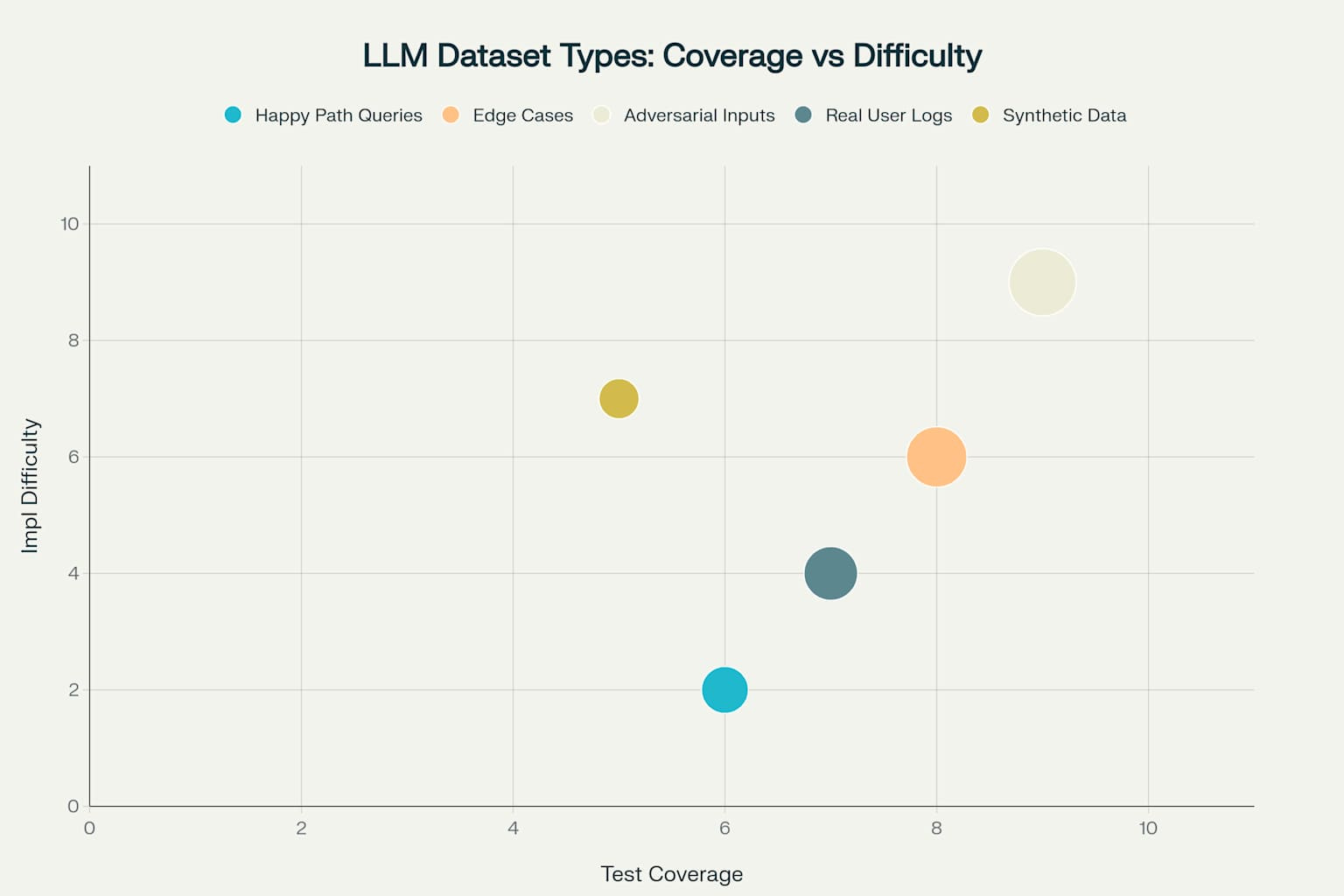
Think in Datasets, Not Unit Tests
With LLMs, you can't test that 2+2=4 and call it done. You need datasets that represent your use case across multiple dimensions
LLM-as-a-Judge Is Your Secret Weapon
Here's the method that's revolutionizing LLM evaluation: use an LLM to evaluate another LLM's output.
The process flows seamlessly: your primary LLM generates a response, then a secondary LLM judges that response using specialized evaluation prompts. Ask specific questions like:
"Is this response based on the retrieved context?"
"Does this follow our brand guidelines?"
"Is this response helpful and concise?"
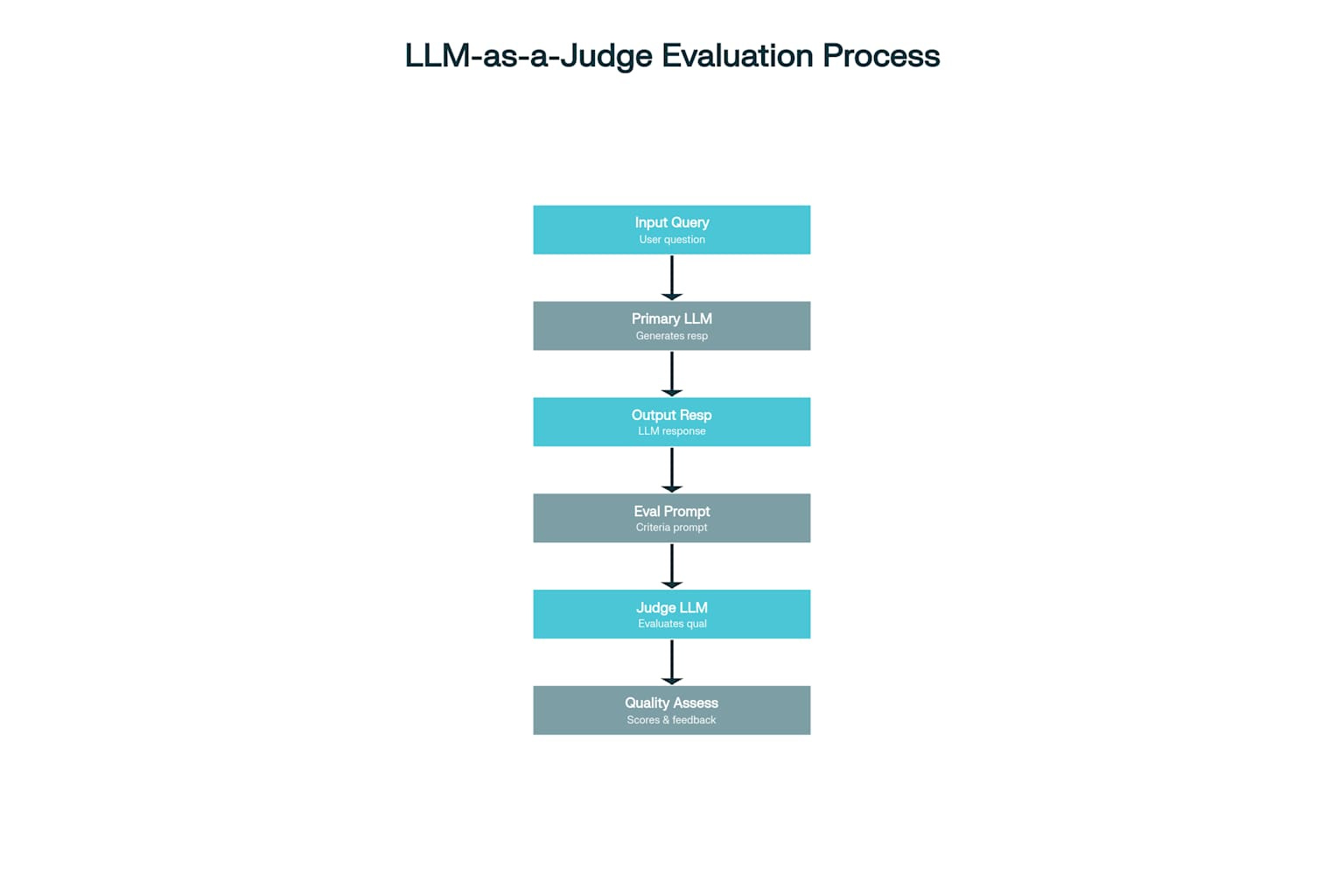
It's like replacing a human labeler for narrow, constrained tasks. And it works surprisingly well.
Remember: your LLM judge is a small ML project itself that needs tuning and evaluation.
Evaluation Is Your Competitive Moat
Building a solid evaluation system takes time, but it's time that creates competitive advantage.
A good evaluation system is like a living product spec that implements "good" in code and datasets. This lets you:
Move faster: Test new prompts and models in hours, not days
Ship with confidence: Know if changes will break things
Build user trust: Especially critical in high-stakes domains
Everyone has access to the same models. But you can have superior labeled data, sharp discriminative tests, and product insights others lack.
Conclusion
Without evaluation, your product is just a prototype. With proper evaluation, you have a systematic way to improve, a competitive moat, and the confidence to ship AI that actually works.
The question isn't whether you need LLM evaluation. It's whether you're ready to build it properly.
Ready to dive deeper? Next articles in series includes hands-on tutorials for implementing these concepts with real code examples.