

Day 5 - Vector Databases
Prerequisite to building specialized LLM models


This is the fifth installment of my 75 Days Of Generative AI series. If you are interested in the previous articles check the index here. Today we cover what Vector Databases are and quick tutorial and loading and retrieving data from one.
The true power of vector databases lies in their ability to provide LLMs with access to real-time, proprietary data. This capability has paved the way for Retrieval Augmented Generation (RAG) applications ( more about it soon! ), which combine the vast knowledge of pre-trained models with up-to-date, domain-specific information.
At their core, vector databases leverage embeddings—high-dimensional numerical representations that capture the semantic essence of data. These embeddings allow the databases to:
Encode meaning: Transform complex data (text, images, audio) into mathematical representations that preserve semantic relationships.
Measure similarity: Efficiently compute the closeness between different data points in the vector space.
Enable rapid retrieval: Quickly sift through massive datasets to identify the most relevant information based on vector similarity.
By harnessing these capabilities, vector databases bridge the gap between raw data and machine understanding, enabling more nuanced and context-aware AI applications.
Well-known Vector DBs are :
ChromaDB
Qdrant
Weaviate
Faiss
Pinecone
What are Embeddings?
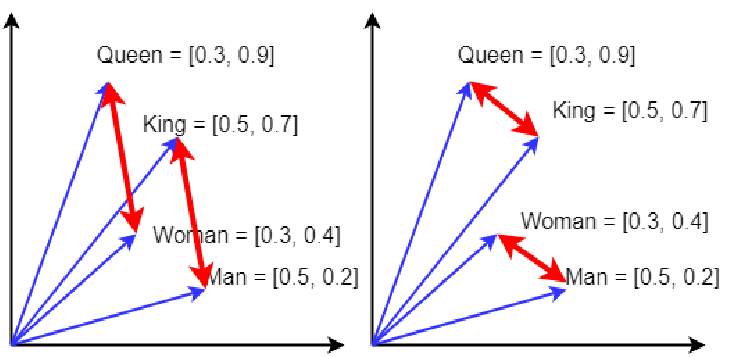
Embeddings are numerical representations of words, phrases, or other data in a high-dimensional space. Each dimension captures some aspect of the word's meaning. For simplicity, let's use a very low-dimensional space (4D) for our example, though real-world embeddings often use hundreds of dimensions.
Imagine we have the following simplified 4-dimensional embeddings:
king = [ 0.5, 0.9, 0.2, 0.1]
queen = [ 0.5, 0.8, 0.2, -0.1]
man = [ 0.3, 0.4, 0.2, 0.1]
woman = [ 0.3, 0.3, 0.2, -0.1]Let's break this down:
The first dimension (0.5 for both king and queen, 0.3 for man and woman) might represent "human."
The second dimension (higher for king/queen) could represent "royalty."
The third dimension is the same for all, possibly representing "adult."
The fourth dimension differentiates gender (positive for male, negative for female).
Now, the famous analogy "king is to queen as man is to woman" can be represented mathematically:
king - queen ≈ man - womanNow
king - queen = [ 0.5, 0.9, 0.2, 0.1] - [ 0.5, 0.8, 0.2, -0.1] = [ 0.0, 0.1, 0.0, 0.2]man - woman = [ 0.3, 0.4, 0.2, 0.1] - [ 0.3, 0.3, 0.2, -0.1] = [ 0.0, 0.1, 0.0, 0.2]As you can see, the results are identical, capturing the relationship between the words.
This simple example demonstrates how embeddings can:
Represent words as vectors in a multi-dimensional space.
Preserve semantic relationships between words.
Allow for mathematical operations that reveal these relationships.
Chat with your document - Loading and Retrieving data
I‘ll be using Langchain and ChromaDB as an example to load a transcript of the machine learning course by Andrew NG and then try to ask a few questions. If you want to know more about Lightning Studio and Langchain check my yesterday’s article
We start by downloading the necessary dependencies
!pip install langchain langchain_community
!pip install -q pypdf # library for reading PDF
!pip install fastembed # embedding library from Qdrant. Its small and fast!
!pip install chromadbThe next step is to load the transcript pdf in memory and split it. This is to efficiently store information in our Vector DB. Langchain is brilliant at these steps and enables us to do it in a few lines of code!
from langchain.document_loaders import PyPDFLoader
docs = []
loader = PyPDFLoader("path_to_file/MachineLearning-Lecture01.pdf")
docs.extend(loader.load())from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1500,
chunk_overlap = 150
)
splits = text_splitter.split_documents(docs)The next step is to lead our embedding model. Here is more information about fastembed .
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
# using smallest embedding model so that it fits in our free GPU and RAM instance
embed_model = FastEmbedEmbeddings(model_name="BAAI/bge-small-en-v1.5")
Create a local instance of ChromaDB
from langchain.vectorstores import Chroma
persist_directory = 'docs/chroma/'Now we create the DB and load the documents into DB after converting them into embeddings
vectordb = Chroma.from_documents(
documents=splits,
embedding=embed_model,
persist_directory=persist_directory
)Time to query the DB!
question = "What is the topic of the class?"
response_docs = vectordb.similarity_search(question,k=3)
len(response_docs)
response_docs[0].page_contentThe output looks like this
Document(metadata={'page': 8, 'source': '/teamspace/studios/this_studio/MachineLearning-Lecture01.pdf'}, page_content="statistics for a while or maybe algebra, we'll go over those in the discussion sections as a \nrefresher for those of you that want one. \nLater in this quarter, we'll also use the disc ussion sections to go over extensions for the \nmaterial that I'm teaching in the main lectur es. So machine learning is a huge field, and \nthere are a few extensions that we really want to teach but didn't have time in the main \nlectures for.")]Not only does the output have the split where the topic is but also some metadata around the output. This is one of the basic examples of querying a Vector DB. Of course, many optimizations need to be done which we will cover while building real-world apps.
Conclusion
Vector databases are crucial in today's AI-driven world, enabling efficient storage and analysis of multi-dimensional data. They power various applications, from recommendation systems to genomic analysis. Notable examples include Chroma, Pinecone, Weaviate, Faiss, and Qdrant. As AI advances, vector databases will play an increasingly important role in data processing across industries, leading to more sophisticated and personalized solutions.
If you like my series follow me on my LinkedIn.