

This is day 7 of my 75 Days Of Generative AI series. Until now, we have been covering basics such as RAG, Vector DB, and running a basic LLM but single notebook examples are usually not even close to an actual implementation. Hence, for the next few days, I’ll be building an end-to-end LLM twin app ( inspired by this repo ).
What is an LLM twin - In short it’s a model which writes like you by learning your previous articles. In my case, I’ll be using my Substack and LinkedIn as the source. By the end of it, I will write an article myself and use evaluation techniques to check how is my LLM twin performing
Data Pipeline - Includes fetching my articles and posts from Substack and LinkedIn and then adding them to a document-based data store ( MongoDB ). We’ll then push this information to a Vector DB ( Qdrant/ChromaDB).
Training Pipeline - We’ll choose an appropriate LLM and use fine-tuning techniques to train the model to understand style of writing we are targeting. If you want to know more about fine-tuning, check this out.
Inference Pipeline - This is the part where we use RAG techniques and combine them with LLM to expose it to a chat interface via a REST API.
Why these multiple pipelines you may ask. The idea is to present a modular architecture that is as close to a production-grade app as possible. We also get to work on other aspects of the GenAI journey like data collection/cleaning and LLMOps.
Data Pipeline

This will consist of 2 python based services which will
Scrape my substack and LinkedIn to get the articles and posts
Run an ETL pipeline to load this data to MongoDB as well as a Vector DB like Qdrant.
Important note: We are crawling only our data, as most platforms do not allow us to access other people’s data due to privacy issues. But this is perfect for us, as to build our LLM twin, we need only our digital data.
Training Pipeline
This is part of the system that will receive data from the Vector store and fine-tune LLM like llama3 or mistral using techniques like QLora.
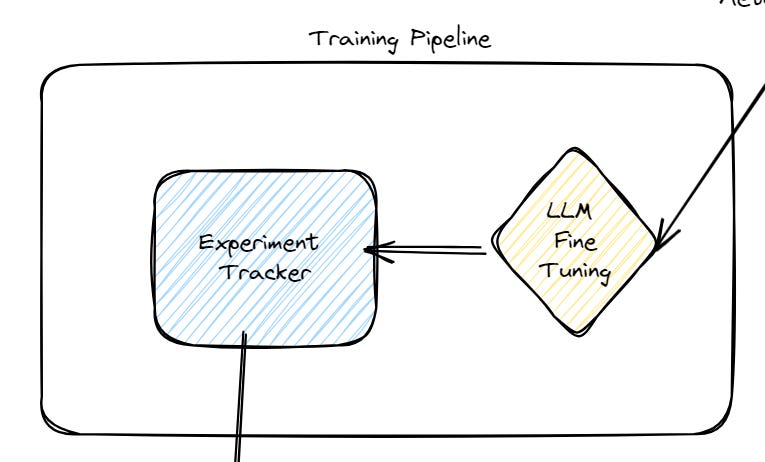
We will also use an experiment tracker like CometML as suggested by the original article to make sure we can compare all our fine-tuning experiments and choose the next performing one.
Inference Pipeline

The inference pipeline, the LLM system's final component, interfaces directly with clients via a REST API. Users can access it through HTTP requests, akin to ChatGPT and similar tools.
Communication patterns
There are some missing parts to the architecture here. The major one is how various pipelines interact with each other. There are 2 ways
Asynchronously via a messaging queue like rabbitMQ
Feature store in case of fine-tuned LLM
Conclusion
Super excited for the next few days where we slowly but surely build an LLM Twin in an end-to-end fashion. There are a lot of areas and tools to cover which we will deep dive into soon. Tomorrow we build our data collection pipeline!
Till then if you like my series follow me on my LinkedIn.